
BLOGUE
Vous connaissez le vieil adage : il n’y a pas de fumée sans feu? En voyant les premiers signes d’un feu, que ce soit la fumée, l’odeur de bois, ou votre détecteur qui sonne l’alarme, vous chercherez probablement à trouver la source du problème pour régler la situation (ou à vous enfuir en courant!). En développement logiciel, c’est la même chose! Cette odeur de fumée, il s’agit des code smells.
Lorsqu’on parle de code smells, il s’agit d’un sujet très vaste sur lequel on pourrait passer des années à publier de l’information pertinente. Aujourd’hui, je vous propose d’entrer doucement dans cet univers en définissant ce qu’est un code smell, à quoi ça sert, comment les reconnaître et vous donner quelques exemples. C’est parti!
C’est quoi un code smell?
Tout d’abord, il s’agit d’un terme inventé par Kent Beck alors qu'il aidait Martin Fowler à écrire son livre sur le refactoring. Il utilisait ce terme pour décrire un élément pouvant indiquer une complexité non nécessaire, qui rend l'évolution du code plus difficile.
Les code smells sont souvent un indicateur, un symptôme d'un problème plutôt que le problème lui-même. Ils peuvent prendre différentes formes, comme la lisibilité, la duplication ou la difficulté d’écrire des tests, par exemple. Ils peuvent se produire aussi bien dans le code de production que dans le code de test.
C’est quelque chose qui indique au développeur : ça ne sent pas bon, je dois analyser plus en profondeur et essayer de trouver la source du problème afin de le corriger.
À quoi ça sert, un code smell?
Les code smells peuvent nous aider à identifier des problèmes de conception courants rapides à repérer (ou à renifler!). On peut ainsi cibler des problèmes qui se produisent partout et à chaque niveau d'abstraction. De plus, ils permettent d’identifier les refactorings, ou les combinaisons de refactorings, qui fonctionnent le mieux pour éliminer ces «odeurs».
En effet, une fois que l’on comprend c’est quoi un smell, on est en mesure de faire des liens avec des techniques de refactoring pour les corriger. Identifier les smells ouvre la porte à une série de pistes de solutions éprouvées, souvent des patterns que les anciens ont construit au fil des ans, ce qui rend la résolution de problèmes beaucoup plus simple.
En tant que développeurs, on a donc intérêt à suivre cette nomenclature et à la maîtriser pour profiter de l’intelligence de la communauté qui nous est servie sur un plateau d’argent. Pas besoin de réinventer la roue tous les jours quand on a un historique de solutions éprouvées par des centaines, voire des milliers de cas de figure!
Comment reconnaître les code smells?
Pour se lancer, il n’y a pas de recette magique, il faut lire des catalogues et se pratiquer à les reconnaître. Vous pouvez également faire des ateliers avec votre équipe : regardez du code ensemble et partagez ce que vous n’aimez pas, mais surtout pourquoi vous n’aimez pas ça. Est-ce que ça a un nom? Il faut gratter. Une fois que vous aurez mis un nom sur le problème, vous aurez des pistes de solutions!

Dans notre domaine, plusieurs éléments peuvent avoir l’air de smells par la complexité du travail. Mais un vrai code smell a plutôt tendance à être complexe par accident (accidental complexity). Par conséquent, il faut bien analyser chaque smell avant de conclure qu’il y a effectivement un problème.
Où peut-on trouver des catalogues de code smells?
Beaucoup de catalogues de code smells sont disponibles en ligne sur des communautés de développeurs. Ces catalogues fournissent un vocabulaire riche et coloré avec lequel les programmeurs peuvent communiquer rapidement sur les problèmes de conception. Certaines catégories existent également afin de voir l’impact que les code smells peuvent avoir à long terme.
Par exemple, dans sa présentation Get a Whiff of This, la développeuse de renom Sandi Metz recense quelques code smells classiques, classés dans différentes catégories :
- Bloaters | long method, large class, data clumps, long parameter list, primitive obsession
- Preventers | divergent change, shotgun surgery, parallel inheritance hierarchies
- Couplers | feature envy, inappropriate intimacy, message chains, middle man
- Abusers | switch statements, refused request, alternative classes with different interfaces, temporary fields
- Dispensables | lazy class, speculative generality, data class, duplicated code
Si l’on prend par exemple les bloaters, il s’agit de code smells qui polluent un code qui pourrait être beaucoup plus simple.
Un exemple de code smell
Dans les codebases qui n’utilisent pas le Domain-Driven Design (DDD), où l’on essaie de se rapprocher du langage du domaine, on retrouve couramment le smell de “primitive obsession” qui fait partie des object-oriented abuser. On l’observe lorsqu’on manipule directement les primitives que le langage nous offre et que l’on doit toujours valider le contenu de ces primitives avant un traitement. Tout ça ajoute de la complexité, très rapidement, en plus de créer beaucoup de duplication! Les différents catalogues de smells et de refactoring vont suggérer d’encapsuler les validations avec les primitives à la construction d’un nouveau concept de domaine. Vous pourrez mettre un mot sur ce nouveau concept et présumer, au moment d’utiliser ce nouveau concept, qu’il contient des données validées.
Les avantages des code smells
- Les code smells sont agnostiques de toutes technos. Ce sont simplement des étiquettes associées à des erreurs potentielles, donc tout le monde peut les utiliser!
- Lorsque tout le monde a une bonne compréhension des smells, ceux-ci facilitent la communication en équipe.
- Ils permettent de trouver des solutions éprouvées plus rapidement.
- Ils sont reliés à la notion de refactoring et facilitent la maintenance.
Plusieurs développeurs sont réticents à faire du refactoring, pour plusieurs raisons : on préfère la réécriture (un gros drapeau rouge!), on a peur de tout briser, on a toujours travaillé comme ça, on n’a pas le temps (aka ce n’est pas valorisé par l’entreprise), on ne connaît pas les patterns, techniques ou meilleures pratiques, ou encore on ne sait par où commencer. Mais souvent c’est tout simplement parce qu’on ne reconnaît pas les signes que le code nous envoie aka, on ne reconnaît pas les smells.
La seule raison valable pour éviter le refactoring, et elle n’est valable que temporairement seulement, est un échéancier à court terme qui nous force à nous concentrer sur une seule chose.
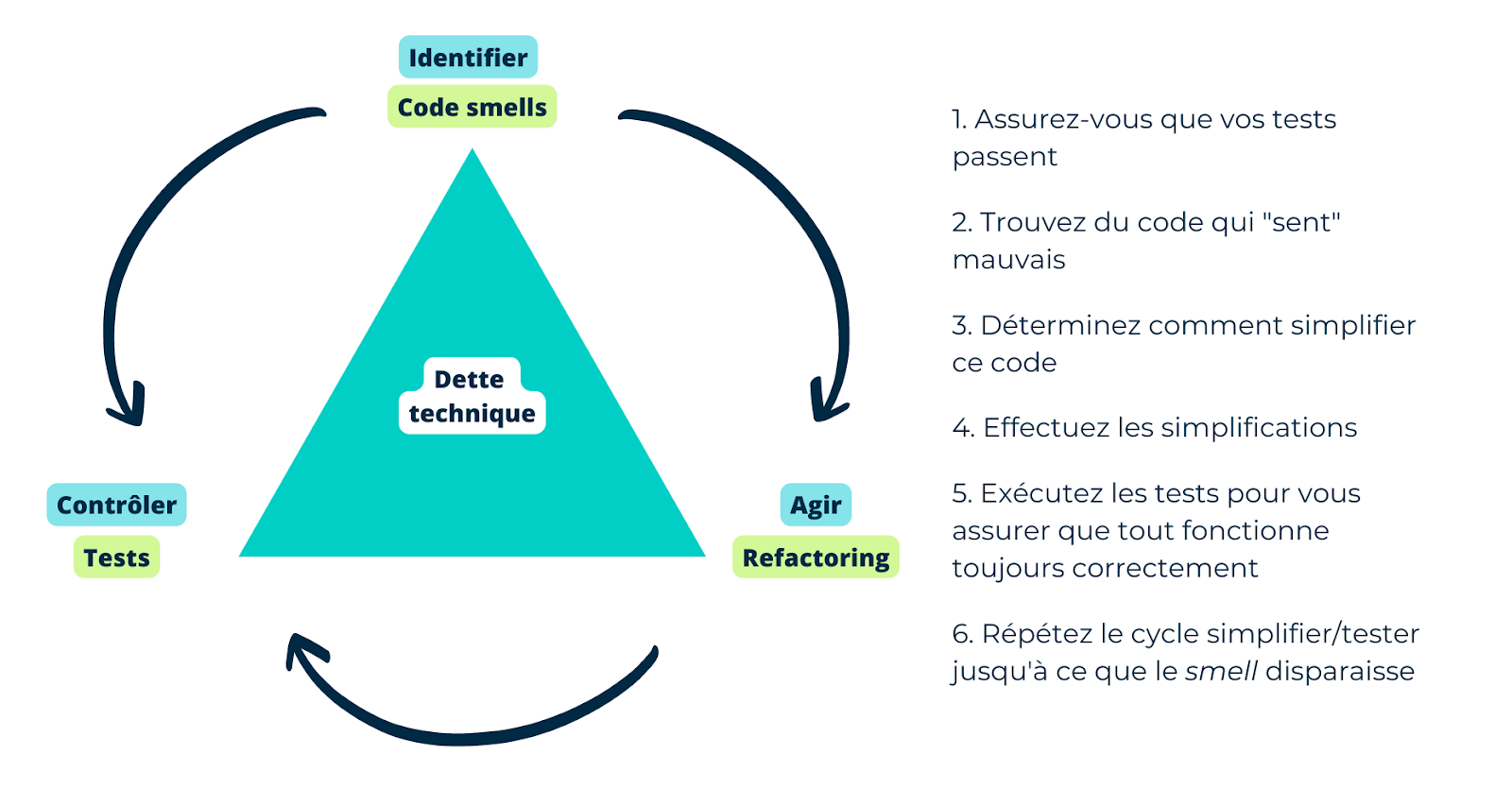
Si vous êtes intéressés au lexique des code smells, je vous suggère aussi de vous intéresser aux concepts de refactoring, de dette technique et de Test-Driven Design (TDD). Tout ça est intimement lié pour garder une architecture évolutive ; l’identification de code smells étant la première étape!
Quelques références et catalogues
- Le livre Refactoring: Improving the Design of Existing Code, par Martin Fowler et Kent Beck. C’est l’ouvrage original qui a parti le bal des code smells! Un chapitre est dédié aux smells et comment on les catégorise.
- Le livre Refactoring to Patterns par Joshua Kerievsky.
- La série Clean d’Uncle Bob. Plusieurs de ses vidéos sont également gratuites!
- Le livre The Mikado Method par Ola Ellnestam et Daniel Brolund.
- Le livre Refactoring for Software Design Smells: Managing Technical Debt par Girish Suryanarayana, Ganesh Samarthyam et Tushar Sharma.
- Le site web Refactoring Guru, qui recense une panoplie de code smells.Le logiciel Sonar Source (disponible en open source) qui soulève les smells potentiels.